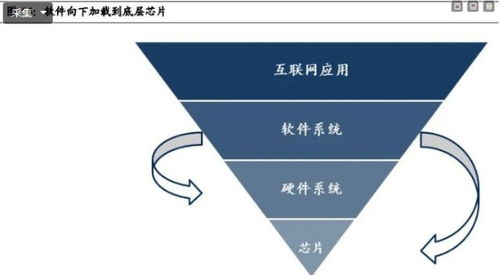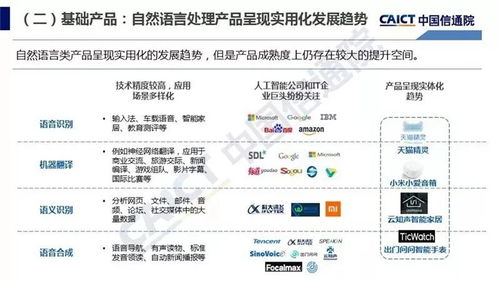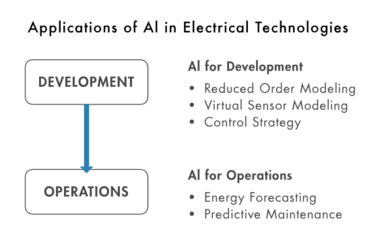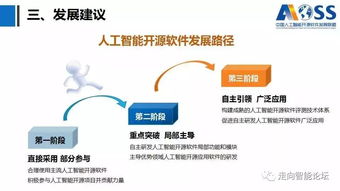
人工智能作為當今科技領域的重要驅(qū)動力,其開源軟件的興起不僅推動了全球技術(shù)共享,也為中國AI產(chǎn)業(yè)的發(fā)展注入了活力。中國在人工智能開源軟件領域的演進,經(jīng)歷了從引進學習到自主創(chuàng)新的過程,展現(xiàn)出獨特的‘前生今生’。
前生:引進與學習階段(2010年代初期至中期)
在人工智能浪潮興起之初,中國主要依賴于國際開源框架,如TensorFlow、PyTorch等。國內(nèi)開發(fā)者通過學習和應用這些工具,逐步積累經(jīng)驗。此階段,中國的貢獻以社區(qū)參與和本地化適配為主,例如百度推出了PaddlePaddle的早期版本,但整體影響力有限。開源生態(tài)尚未成熟,更多是技術(shù)追隨者角色。
今生:自主創(chuàng)新與生態(tài)構(gòu)建(2010年代末至今)
隨著政策支持和市場需求增長,中國AI開源軟件進入高速發(fā)展期。以百度的PaddlePaddle、華為的MindSpore、阿里的MNN等為代表,國產(chǎn)框架逐漸成熟,并在性能、易用性上實現(xiàn)突破。這些工具不僅服務于本土應用,還通過開源社區(qū)吸引全球開發(fā)者。同時,中國在自然語言處理、計算機視覺等領域推出大量開源模型和工具庫,如清華的CPM系列、百度的ERNIE,推動了AI應用軟件的普及。開源生態(tài)的完善,促進了產(chǎn)學研結(jié)合,加速了AI技術(shù)在醫(yī)療、金融、自動駕駛等行業(yè)的落地。
人工智能應用軟件開發(fā)的實踐與挑戰(zhàn)
在應用層面,中國AI開源軟件為開發(fā)者提供了豐富資源,降低了技術(shù)門檻。例如,使用PaddlePaddle可以快速構(gòu)建圖像識別系統(tǒng),而開源數(shù)據(jù)集和預訓練模型則簡化了模型訓練過程。挑戰(zhàn)依然存在:一是核心技術(shù)依賴問題,部分底層算法仍受制于國外框架;二是開源社區(qū)活躍度與國際化程度有待提升;三是數(shù)據(jù)隱私和倫理規(guī)范需進一步健全。未來,中國需加強基礎研究投入,推動開源協(xié)作,以在全球AI競爭中占據(jù)更主動地位。
中國人工智能開源軟件從‘前生’的借鑒學習,到‘今生’的自主崛起,體現(xiàn)了技術(shù)本土化的韌性。隨著5G、物聯(lián)網(wǎng)等新技術(shù)的融合,AI應用軟件開發(fā)將迎來更廣闊前景,中國有望成為全球開源生態(tài)的重要貢獻者。